The Basics of Search Engine Friendly Design and Development
Search engines are limited in how they crawl the web and interpret content. A web page doesn’t always look the same to you and me as it looks to a search engine. In this section, we’ll focus on specific technical aspects of building (or modifying) web pages so they are structured for both search engines and human visitors alike.
 Indexable Content
Indexable Content
 In order to be listed in the search engines, your most important content should be in HTML text format. Despite the advances in search engine crawling technology, page elements like Images, Flash files, Java applets, and other non-text content are often ignored or devalued by search engine spiders. The easiest way to ensure that the words and phrases you display to your visitors are visible to search engines is to place them in the HTML text on the page. However, more advanced methods are available for those who demand greater formatting or visual display styles:
In order to be listed in the search engines, your most important content should be in HTML text format. Despite the advances in search engine crawling technology, page elements like Images, Flash files, Java applets, and other non-text content are often ignored or devalued by search engine spiders. The easiest way to ensure that the words and phrases you display to your visitors are visible to search engines is to place them in the HTML text on the page. However, more advanced methods are available for those who demand greater formatting or visual display styles:
- Images can be assigned “alt attributes” in HTML, providing search engines a text description of the visual content.
- Search boxes can be supplemented with navigation and crawlable links.
- Flash or Java plug-ins containing content can be supplemented with text on the page.
- Video & audio content should have an accompanying transcript if the words and phrases used are meant to be indexed by the engines.
Seeing like a Search Engine
Many websites have problems with indexable content, so the practice of double-checking your web page is worthwhile. By using tools that simulate Google’s search engine spiders you can see what elements of your content are visible and indexable to the engines.
Here are a few of the cache and spider tools I use:
- Google Cache
To view Google’s cache of your web page, you can use the cache: search operator. Add the following search string to your browser’s URL and then the domain name you want to check.
cache:http://www.yourdomain.com/
![]() READ: The Google Guide: Cached Pages offers a detailed explanation of “how” the Google cache works. Google Cache is especially handy if you’re looking for a Web site that is no longer there (for whatever reason), or if the Web site you’re looking for is down due to an unusually high volume of traffic.
READ: The Google Guide: Cached Pages offers a detailed explanation of “how” the Google cache works. Google Cache is especially handy if you’re looking for a Web site that is no longer there (for whatever reason), or if the Web site you’re looking for is down due to an unusually high volume of traffic.
This tool simulates a Search Engine by displaying the contents of a webpage exactly how a Search Engine would see it. It also displays the hyperlinks that will be followed (crawled) by a Search Engine when it visits the particular webpage.
Enter your web address (URL) and click “test”. This tool will display return a wide range of information including Googlebot access, mobile readiness, website security, user accessibility, page speed, robots.txt file, sitemap, find page links (including paid links), validate HTML code, page headers and more. These are the same elements that search engine spiders (crawlers, bots) collect from your web page.
This tool simulates a search engine by displaying the contents of a web page in exactly the way the search engine bot would see it and informs you of the most prominent or inaccessible page elements.
Try it you yourself. Choose one of the spider simulators above and enter your web page address. What are the results you see? Are there any errors or unexpected results?
By double-checking the pages you’re building (including your images and links), you can eliminate crawling errors allowing your web page the best opportunity for inclusion (and ranking) in the search engines.
Creating Crawlable Websites
Just as search engines need to see content in order to list pages in their massive keyword-based indexes, they also need to see links in order to find the content. A crawlable link structure – one that search engine spiders can access the pathways of a website – is vital in order to find all of the pages on a website.
One of the most common mistakes in website development is creating website navigation in ways that search engines cannot access web pages. This impacts the ability to get pages indexed in search engines.
Below, I’ve illustrated how this problem can happen:
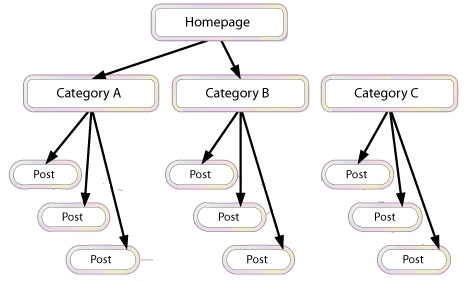
In the example above, search spiders can reach category “A” and “B” and see links to three posts in each category. However, the spiders cannot reach category “C” or any of the linked posts even though category “C” might be the most important content on the site, the spider has no way to reach them (or even know they exist.) This is because no direct, crawlable links point to those pages. As far as search engines are concerned, they might as well not exist – great content, good keyword targeting and smart marketing won’t make any difference at all if the spiders can’t reach those pages in the first place.
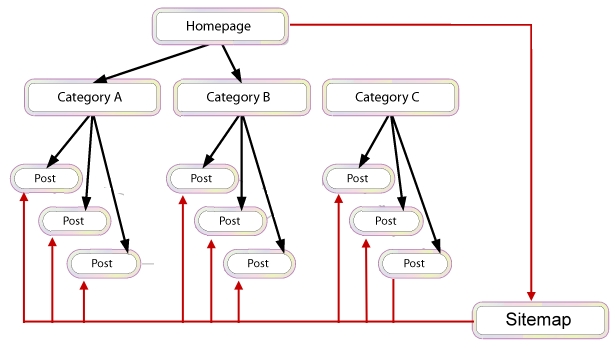
By using good practices in your website construction, you can “build in” preventive measures that can still have your content indexed by the search engine spiders. In this example, a sitemap links to all of the internal content – a search spider can reach the sitemap from the home page.
Why Web Pages are Unreadable..
There are several reasons why web page content is unreadable to search engines. By avoiding some of these common pitfalls, you can ensure you will have crawlable content…
- Submission-required forms
If you require users to complete an online form before accessing certain content, chances are search engines may never see those blocked pages. Forms can include a password protected login area, survey page, or data collection form. In any case, search spiders generally will not attempt to “submit” forms and thus, any content or links that would be accessible via a form are invisible to the engines.
- Links in un-parseable JavaScript
If you use JavaScript for links, you may find that search engines either do not crawl or give very little weight to the links embedded within. Standard HTML links should replace JavaSscript (or accompany it) on any page where you’d like spiders to crawl.
- Links pointing to pages blocked by the meta robots tag or robots.txt file
The Meta Robots tag and the robots.txt file both allow a site owner to restrict spider access to content. Just be warned that many a webmaster has unintentionally used these directives as an attempt to block access by rogue bots, only to discover that “good” search engine bots were blocked too.
- Frames or I-frames
Technically, links in both frames and I-Frames are crawlable, but both present structural issues for the search engines in terms of organization and following. It would be best to stay away from this type of page structure unless you’re an advanced user with a good technical understanding of how search engines index and follow links in frames.
- Robots don’t use search forms or boxes
Although this relates directly to the above warning on forms, it’s such a common problem that it bears repeating… If you use a search form (search box) on your website, do not rely on this link for the search spiders to crawl your content. Spiders don’t perform searches to find content and any content on your site hidden behind inaccessible walls will remain invisible until a spidered page links to it.
- Links in flash, java, or other plug-ins
Although the results of using flash and java can be visually attractive, the links embedded inside of code is often difficult for search engines to read resulting in search spiders unable to crawl through the site’s link structure, rendering them invisible to the engines (and un-retrievable by searchers performing a query).
- Links on pages with thousands of links
Search engines will only crawl so many links on any given page – not an infinite amount. This loose restriction is necessary to cut down on spam and conserve rankings. Pages with 100’s of links on them are at risk of not getting all of those links crawled and indexed.
Matt Cutts, former head of Spam at Google, recommends using less than 100 links per page. Keep in mind, each outbound link on a page is dividing the PageRank of that page between the number of links. Hundreds of outbound links will diminish the PageRank to a minuscule amount. Users often dislike link heavy pages too, so before you go overboard putting a ton of links on a page, ask yourself what the purpose of the page is and whether it works well for the user experience.
![]() As Google develops better tools for crawling web pages, the debate for how many links on page continues. For more information about page links, read this article published in Moz.com by Dr. Peter J. Meyers: How Many Links is Too Many?.
As Google develops better tools for crawling web pages, the debate for how many links on page continues. For more information about page links, read this article published in Moz.com by Dr. Peter J. Meyers: How Many Links is Too Many?.
Robots.txt File
Website developers can use a robots.txt file to give search engine spiders instructions about which parts of your website you do not want them to crawl – this is called “The Robots Exclusion Protocol.”
Here’s how it works:
- A search spider visits your website – www.yourdomain.com.
- Before it crawls your pages, it first checks for any exclusions at www.yourdomain.com/robots.txt and finds
User-agent: *
Disallow: /images/
The “User-agent: *” means this section applies to all robots. The “Disallow: /images/” tells the robot that it should not visit any pages within the /images/ directory.
Before creating robots.txt files, there are two major considerations you should consider
- Search spiders can ignore your /robots.txt file. Especially malware spiders that are scanning the web for security vulnerabilities or email address harvesters used by spammers.
- Once you publish a /robots.txt file, it is publicly available for anyone to view and they will know which sections of your website you don’t want spiders to see. Bottom line, don’t try and use /robots.txt to hide information.
![]() READ: Robotstxt.org provides detailed information about /robots.txt files, how to use them, a database of data collection spiders, robots.txt file checker, and IP lookup (to find out which spiders are visiting your website.
READ: Robotstxt.org provides detailed information about /robots.txt files, how to use them, a database of data collection spiders, robots.txt file checker, and IP lookup (to find out which spiders are visiting your website.
Technical Assistance
There are millions of articles written on how to rank websites and the best techniques for “gaming” the ranking system. Before you try your hand at manipulating the search results, I recommend you have a thorough understanding of the basics. Once you have a ‘baseline’ of what search engines expect, you can push the boundaries and see how far you can go.
Google provides a great starting point to making sure your website is technically correct. By following their suggestions, you will be on the right path to helping Google (and others) find, index and rank your web pages.
Similar to Google, Bing offers a lot of information to help webmasters (and SEO’s) get things right. Their Webmaster support offers a lot of tips, FAQ’s, tools and advanced topics to point you in the right direction for ranking web pages.
-> There’s more to the internet than Google and Bing Yahoo… If you’re going for an international audience then your going to have to know how other search engines operate.
Baidu is China’s largest search and quickly gaining on Google as it climbs in popularity. If you’re creating content for the Asian side of the planet, it’s important to understand how this platform works.
Yandex is the dominating search engine for Eastern Europe – specifically targeting Russia, Ukraine, Belarus, Kazakhstan, and Turkey. Similar to Google, Yandex offer search, email, and other internet related products and services.
Bonus Reading
![]() READ: The World Wide Web Consortium (W3C) is an international consortium that develops the technical specifications and guidelines for HTML, CSS, audio and video, mobile web, JavaScript, accessibility, privacy, graphics (and a lot more) that the World Wide Web unanimously operates. I strongly suggest you read through (and bookmark) this treasure trove of data regarding how the internet operates.
READ: The World Wide Web Consortium (W3C) is an international consortium that develops the technical specifications and guidelines for HTML, CSS, audio and video, mobile web, JavaScript, accessibility, privacy, graphics (and a lot more) that the World Wide Web unanimously operates. I strongly suggest you read through (and bookmark) this treasure trove of data regarding how the internet operates.