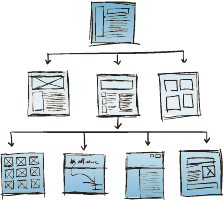
Website architecture is the last “controllable” site element. The right architecture can help your SEO efforts take off while the wrong one hold you back.
![]() READ: A web developer approaches information architecture in terms of fields in a database and how each field will be used on different web pages. A search engine professional thinks in terms of indexation and Pagerank; Shan Thurow offers a middle ground in her article: “SEO vs. Web Site Architecture.”
READ: A web developer approaches information architecture in terms of fields in a database and how each field will be used on different web pages. A search engine professional thinks in terms of indexation and Pagerank; Shan Thurow offers a middle ground in her article: “SEO vs. Web Site Architecture.”
![]() READ: Clear up some of the confusion and misconceptions of Information Architecture (or IA) with this article by Kim Krause Berg: “Site Navigation & Information Architecture Fundamentals for SEOs.”
READ: Clear up some of the confusion and misconceptions of Information Architecture (or IA) with this article by Kim Krause Berg: “Site Navigation & Information Architecture Fundamentals for SEOs.”
Crawlability and Indexation
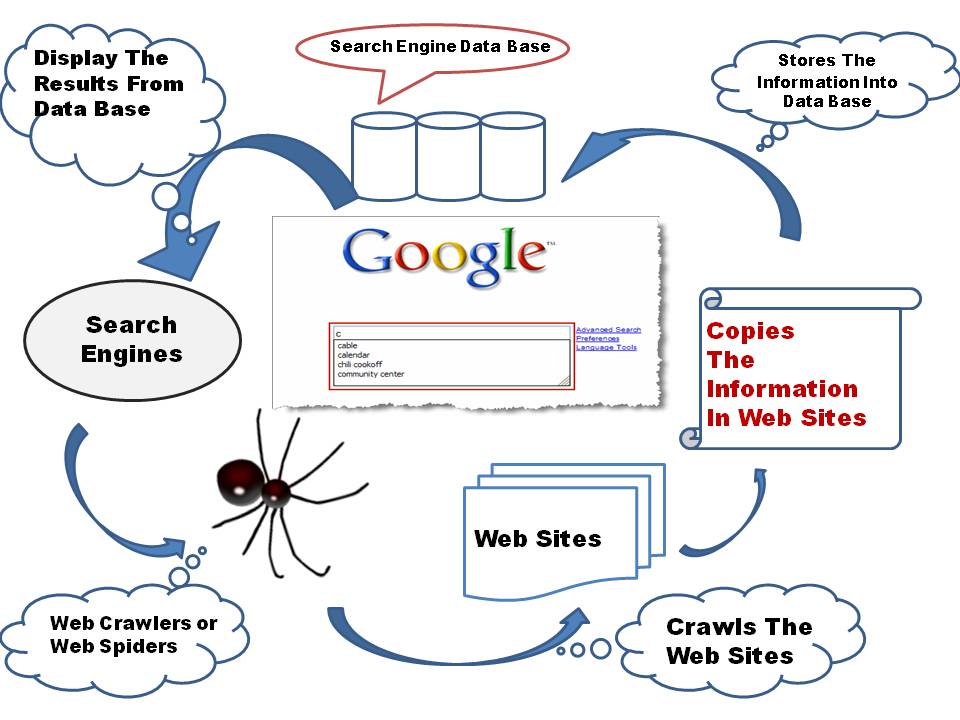
Even though the two concepts are interrelated – they are not the same thing.
 Crawlability
Crawlability
Search spiders find information by “crawling” websites and links similar to the way you navigate the pages of a website. They go from link to link and bring data about those web pages back to their servers to include in their index..
The crawl process begins with a list of web addresses from past crawls and sitemaps provided by website owners. As the spiders visit (crawl) these websites, they look for links for other pages to visit, paying attention to new sites, changes to existing sites and dead links; they make copies of the web pages to be stored in their index, and they put each page through filters to determine relevancy and importance.
Common Crawl Problems
- Broken links (404)
- Poor internal linking
- Complex URL
- Dynamic pages
- Code bloat
- Error in robots.txt file
- Orphan pages
- Moving your site (301)
- Moving your pages (404)
- No site maps
- Fancy technology
Best Practices
Most crawl issues can be avoided by avoiding page elements that can cause problems…
- Navigation
JavaScript or Flash can potentially hide links, making the web pages those links lead to hidden from search engines which can cause the actual web pages to be hidden from the search spiders.
- Robots.txt
The use of a robots.txt file can assist search spiders by instructing which URL’s not to crawl, thus increasing efficiency.
- Sitemaps
Providing sitemaps in both HTML and XML makes it easier for search engines to crawl your website.
Indexation
This second process is called indexation. Crawling precedes indexation – the index (database) is a subset of the crawl.
Think of the web as an ever-growing public library with billions and billions of books – and no central filing system. As search spiders crawl the internet gathering web pages they record the data and store the information in an index – the file system – so they know exactly how to look things up.
The process is a lot more complex than that… Algorithms filter the data to determine what is most relevant or how important each bit of data is so that search queries can return the best response. When you search for “dogs” you don’t want a page with the word “dogs” on it hundreds of times. You probably want pictures, videos or a list of breeds. Indexing systems note the various aspects of pages, such as when they were published, whether they contain pictures and videos, and much more.
Sorting It Out
Although most websites don’t need to set up restrictions for crawling, indexing or serving, website owners have choices.
To Be or Not to Be
Site owners have choices of how and where their websites are crawled with the robots.txt file. Site owners can even choose not to be crawled by search spiders.
How Do I Look?
By providing specific instructions about how to process pages on their websites, web site owners can choose how content is indexed on a page-by-page basis. For example, they can opt to have their pages appear without a snippet or a cached version. Site owners can also integrate search into their own pages with a custom search.
![]() READ: When thinking about the quality of your website – consider the bigger picture – what your visitor wants. Josh McCoy offers advice in his post: “Website Indexation Audit: How to Find & Remove Non-Essential Content.”
READ: When thinking about the quality of your website – consider the bigger picture – what your visitor wants. Josh McCoy offers advice in his post: “Website Indexation Audit: How to Find & Remove Non-Essential Content.”
URL Structures
URL’s (short for Unique Resource Locator) are the ‘address’ for a specific document available on the web and one of the most fundamental building blocks for SEO. It’s important to pay attention to URL’s as they appear in multiple important locations and the easier you make it for your audience (and the search engines) to find you – the better.

Search Results
Since search engines display URLs in their results, they can impact click-through and visibility. URLs are also used in ranking documents, and the web page whose names includes the queried search term receives some added benefit if keywords were used.
Browser Address Bar
URLs also make an appearance in the web browser’s address bar. This has no impact on ranking, but poor URL structures and site design can result in a negative user experience.
Anchor Text Hyperlink
URL’s are often copy and pasted into other locations as your site visitors share the content with others. Poor URL structures can influence click-through to your website.
URL Best Practice
1. Try and Use a Single Domain
There is plenty of evidence illustrating that content contained within a domain and subfolder typically outranks a domain and subdomain structure – and even more examples of people moving their content from a subdomain to subfolder and seeing improved results (or, worse, moving content to a subdomain and losing traffic).
Whatever algorithm search engines use to rank content, there seems to be a consistent problem with search engines passing authority to subdomains versus subfolders.
2. Make URL’s Readable
Can your visitors find the information they want? Look at your URL’s – are they easily and accurately predicting the content you’d expect to find on the page? URL’s are another location where you can help visitors with an appropriate description.
3. Keyword Use is Important (but Overuse is Dangerous)
If your page is targeting a specific term or phrase try to include it in the URL, but don’t go overboard by stuffing in multiple keywords for SEO purposes – overuse will result in less usable URLs and can trip spam filters.
URLs get copied and pasted regularly, and when there’s no anchor text used in a link, the URL itself serves as that anchor text (and having your keyword in the URL is still a powerful input for rankings).
When keywords appear in search results, research has shown that the URL is one of the most prominent elements searchers consider when selecting which site to click.
4. Avoid Canonicalization
Is your content accessible from different URL’s? If you have very similar content served from different URL’s you should consider canonicalizing them with either a 301 redirect (if there’s no real reason to maintain the duplicate) or a rel=canonical (if you want to maintain slightly different versions for some visitors, e.g. a printer-friendly page).
Duplicate content isn’t really a penalty (unless you’re duplicating at very large scales), but it can cause search engines to be confused which will negatively affect your ranking. Read the section (Canonicalization “ca-non-ick-cull-eye-zay-shun” – What’s That?) below for more information.
5. Avoid Dynamic URLs
The best URLs are human readable without lots of parameters, numbers and symbols. Using technologies like mod_rewrite for Apache, ISAPI_rewrite for Microsoft and URL Rewrite Module for IIS you can easily transform dynamic URLs like this: http://yourdomain.com/blog?id=123 into a more readable static version like this: http://yourdomain.com/blog/google-fresh-factors. Even single dynamic parameters in a URL can result in lower overall ranking and indexing.
6. Shorter is Better
While a descriptive URL is important, minimizing length and trailing slashes will make your URLs easier to use. This isn’t a technical issue (most browsers can handle a 2,000 +/- character URL) – it’s a usability and user experience issue. Shorter URL’s make it easier for your audience to copy and paste URLs into emails, blog posts, text messages, social media sites, etc and your URL will be visible for all to see. If it’s easy for your audience to use then it’s easy for search engines too.
7. Match URL’s to Titles
Keeping the page URL and the page title/headline (which engines display prominently on their search results pages) closely related, you are creating a sense what the searcher will find on your page. When they click on your link, that expectation is delivered with the title/headline reinforcing the URL.
The headline/title and URL do not have to be identical, but you should strive a level of clarity that your audience will understand.
8. Eliminate Stop Words in URL’s
I’ve already suggested keeping URL’s short. By removing stop words (and, or, but, of, the, a, etc.) from your title/headline, you can make your URL’s shorter without sacrificing readability. Use your best judgement on whether to include or not based on the readability vs. length.
9. Remove Problem Causing Punctuation Characters
I’ve already mentioned that using punctuation makers within Meta tags can cause problems – they can cause problems within URL strings too. It’s best practice to remove (or control) these troublesome characters from your URL’s.
There’s a great list of safe vs. unsafe characters available on Perishable Press:
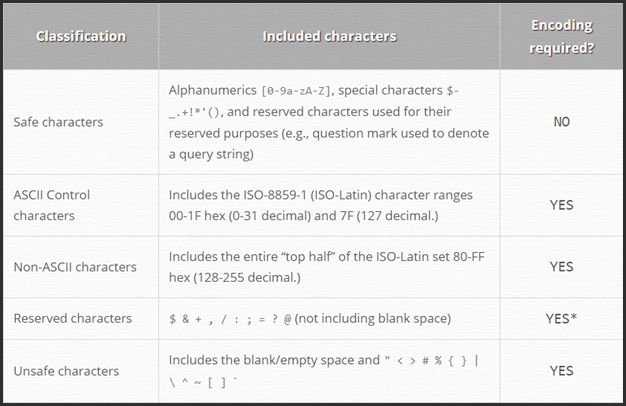
It’s not only the potential for breaking certain browsers, crawlers, or proper parsing these characters cause – they are harder for your audience to read too.
10. Limit Redirection
It’s common for content to move within a website and use redirection to point to the new location, but when this redirect string occurs more than twice you could get into trouble.
Why? Search engines do not have a problem following long redirect hops, but each time they jump to the new location, they consider the content “less important” and may not follow or count the ranking signals of the redirecting URLs as much.
The bigger trouble is for browsers and users… Each hop takes time for the browser to load (especially on mobile browsers). Longer load times will lead to site visitor frustration and they will eventually look for content somewhere more accessible. Keep redirects to a minimum and you’ll set yourself up for less problems.
11. Content Organization and Folders
Generally the fewer folders in the file path the better. Long file paths do not harm performance, but they could create a perception problem for search engines (and your audience) as well as making URL’s edit more complex. Best practice is to use your judgement and think “long term” when creating websites.
12. Using Hash tags in URLs
Historically, using a hash (#) in your URL has been for one of two reasons:
Hashes (or URL fragment identifier) can be used to send visitors to a specific location on a given page.
Hashes can also be used as part of a tracking parameter (e.g. domain.com/keyword#src=facebook).
Using URL hashes for anything else is typically a bad idea – especially if you are using them to send visitors t0 unique content. There are always exceptions (such as dynamic AJAX linking applications), but simple statically written URL’s will have the most benefit.
13. URLs and Case Sensitivity
Linux/UNIX servers can interpret separate cases. That means www.domain.com/AbC is a different URL than www.domain.com/aBc. Best practice is to avoid using upper case characters in your URL’s. If you encounter a client whose website was created with mix of upper and lower case characters URL’s, you can use htaccess rewrite protocols to assist (like this one) with the problem.
14. Use-Hyphens-to-Separate-Words-in-URL
Not all web applications can interpret separators like underscore “_,” plus “+,” or space “%20” correctly. Best practice would be the use of the hyphen “-” character to separate words in a URL.
Example:
http://www.yourdomain.com/use-hyphens-to-separate-words-in-url.html
15. Keyword Stuffing URL’s
Repeating keywords in your URL (and site content) is pointless and makes your site look spammy. Google and Bing have advanced their algorithms past the time when keyword stuffing was rewarded with higher rankings. Today you will most likely receive a penalty! And searchers will be turned off by the repetition – don’t hurt your chances of earning a click (which CAN impact your rankings) by overdoing keyword matching/repetition in your URLs.
![]() READ: Some people suggest that URL structure doesn’t matter and that search engines are capable of making sense of any type of URL or URL structure – In most cases those people are web developers ;-). For a deeper understanding of URL structures read this article by Clark Boyd: 8 SEO Tips to Optimize Your URL Structure.
READ: Some people suggest that URL structure doesn’t matter and that search engines are capable of making sense of any type of URL or URL structure – In most cases those people are web developers ;-). For a deeper understanding of URL structures read this article by Clark Boyd: 8 SEO Tips to Optimize Your URL Structure.
Simple Problems to Avoid
Canonicalization “ca-non-ick-cull-eye-zay-shun” – What’s That?
One of the biggest problems any website faces is canonicalization. At the root of the problem is duplicate content and canonicalization occurs when you have the same content appearing at different URL’s within your website.
Example:
www.example.com
example.com/
www.example.com/index.html
example.com/home.asp
All of these URL’s point to the same location… But search engines see these are four uniques address and they would expect unique content from each location.
![]() READ: Matt Cutts (head of Google Spam) has addressed this issue and offers some good advice on solving the problem in the article: Matt Cutts: Gadgets, Google, and SEO.
READ: Matt Cutts (head of Google Spam) has addressed this issue and offers some good advice on solving the problem in the article: Matt Cutts: Gadgets, Google, and SEO.
Best Practice
By using best practices during your website development, you can avoid the problem completely.
- Choose a Preferred Domain Path
By choosing your domain preference (either www or non-www addresses) you can avoid many duplicate issues within your site.
- Use the Canonical Tag
Another option to combating duplicate content is to use the “Canonical URL Tag.” This option will reduce duplicate content issues on a single site and it can also be used across different websites (from one URL on one domain pointing to a different URL on a different domain).
Example:
<link rel=”canonical” href=”http://yourdomain.com/blog”/>
The “target” of the canonical tag points to the “master” URL that you want to specify as original (and rank for).
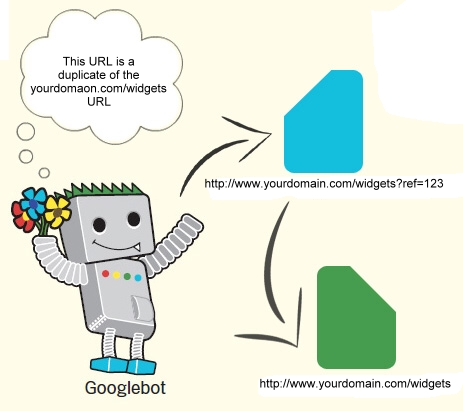
Using the tag informs the search engines that the page in question (http://www.yourdomain.com/widgets?ref=123) should be treated as though it were a copy of the URL (http://www.yourdomain.com/widgets) and that all of the link & content metrics the engines apply should flow back to that URL.
From an SEO perspective, using the canonical tag is similar to a 301 redirect. You’re telling the engines that multiple pages should be considered as one (which a 301 does), without actually redirecting visitors to the new URL
![]() READ: For a complete understanding of canonicalization and solutions to the problem, read the Google Webmaster Tools section on canonicalization.
READ: For a complete understanding of canonicalization and solutions to the problem, read the Google Webmaster Tools section on canonicalization.
Duplicate Content
Duplicate content occurs when the same content appears on different websites.
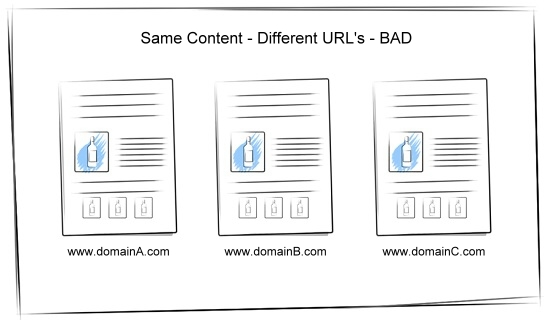
Similar to canonicalization, this can present a major challenge to the search engines and they have been cracking down with penalties and lower rankings.
The three biggest problems with duplicate content are:
- Search engines don’t know which version(s) to include/exclude from their index.
- Search engines don’t know whether to direct the link metrics (trust, authority, anchor text, link juice, etc.) to one page, or keep it separated between the multiple versions.
- Search engines don’t know which version(s) to rank for query results.
Duplicate content can occur for many reasons, the most common are:
- Discussion forums that can generate both regular and stripped-down pages targeted at mobile devices
- Store items shown or linked via multiple distinct URLs
- Printer-only versions of web pages
If your site contains multiple pages with largely identical content, you need to indicate your preferred URL to the search engines. In some cases, content is deliberately duplicated across domains in an attempt to manipulate search rankings. Google has released updates addressing these deceptive practices to ensure an excellent search query experience.
![]() READ: For a complete understanding of duplicate content and solutions to the problem, read the Google Webmaster Tools section on duplicate content.
READ: For a complete understanding of duplicate content and solutions to the problem, read the Google Webmaster Tools section on duplicate content.
![]() READ: In the last couple of years, Google has made some major changes to their algorithm and the Penguin and Panda updates both address duplicate issues. Dr. Pete J. Meyers offers an excellent article on duplicate content and ways to avoid Google penalties in “Duplicate Content in a Post-Panda World.”
READ: In the last couple of years, Google has made some major changes to their algorithm and the Penguin and Panda updates both address duplicate issues. Dr. Pete J. Meyers offers an excellent article on duplicate content and ways to avoid Google penalties in “Duplicate Content in a Post-Panda World.”
Other Considerations
![]() Content Snippets
Content Snippets
Content snippets (aka rich snippets) are a type of structured data that allow webmasters to mark up content in ways that provide information to the search engines. Ever see a 5 star rating in a search result? Chances are that information was generated by the information from a rich snippet and embedded on the web page.
The use of structured data is not a required element of search friendly design, however, it is quickly being adopted by web developers and those who use it may experience an advantage.
![]() READ: For more information about structured data and examples of data that can benefit from structured markup, visit Schema.org. Schema.org provides a shared markup vocabulary that makes it easier for web developers to decide on a markup schema and get the maximum benefit for their efforts.
READ: For more information about structured data and examples of data that can benefit from structured markup, visit Schema.org. Schema.org provides a shared markup vocabulary that makes it easier for web developers to decide on a markup schema and get the maximum benefit for their efforts.
![]() READ: Google offers a “Rich Snippet Testing Tool” that will check your markup and make sure that Google can extract the structured data (rich snippets markup, meta data, authorship information, and PageMaps) from your page. You can read more rich snippets, testing your markup and structured data on the Google developers website.
READ: Google offers a “Rich Snippet Testing Tool” that will check your markup and make sure that Google can extract the structured data (rich snippets markup, meta data, authorship information, and PageMaps) from your page. You can read more rich snippets, testing your markup and structured data on the Google developers website.
Content Scraping
You work hard on your website. You perform proper keyword research, you create an SEO friendly website using best practices, and you craft exceptional content that your site visitors love – only to find out someone has been scraping your content and stealing your rankings.
The practice of crawling websites for content and re-publishing on their own site is called “scraping” and someone will do it to you. Don’t worry, there are a few things you can do:
- When you publish content using any type of feed format (RSS, XML, ATOM, etc), make sure you ping your content to established ownership. You will find instructions on most major blogging platforms ((like Google, Technorati, WordPress.com) or you can a ping service (like Pingomatic) to automate the process.
- Luckily, most scrapers are lazy – that’s why they are using someone else’s content – and you can use that against them. Most scrapers will re-publish content without any editing, including any links back to your site or any specific post you’ve authored. By using absolute links rather than relative links in your internal structure, you can ensure that the search engines see most of the scraped content linking back to you.
Example:
Instead of relative linking: <a href=”../>Home</a>
Use absolute linking: <a href=”http://yourdomain.com”>Home</a>
This way, when a scraper copies your content, the internal links will remain pointing to your site.
- No matter what you do – nothing is foolproof. Expect your content to be scraped. Usually you can just ignore it, but if it gets severe and you find that you are losing rankings and traffic, you might consider taking legal action through a process called DMCA takedown.
![]() READ: To find out more about how to combat copyright infringement using the DMCA (Digital Millennium Copyright Act), read this article by Sarah Bird: Four Ways to Enforce Your Copyright: What to Do When Your Online Content Is Being Stolen.
READ: To find out more about how to combat copyright infringement using the DMCA (Digital Millennium Copyright Act), read this article by Sarah Bird: Four Ways to Enforce Your Copyright: What to Do When Your Online Content Is Being Stolen.
Bonus Reading
Because your website’s architecture has such an important impact on ranking, I have included some additional reading materials. This will not be included on the quiz, but I do recommend you read them all.
- Joost De Valk (Yoast.com): Intelligent Site Structure for Better SEO
- Bruce Clay (BruceClay.com): SEO Siloing: How to Build a Website Silo Architecture
- Bruce Clay (BruceClay.com) Tips for SEO Web Design and Site Architecture
- Sujan Pate (Search Engine Journal): SEO 101: How your Website’s Structure Affects its SEO